머신러닝 시스템의 종류와 텐서플로우 알고리즘 종류
#머신러닝 시스템의 종류와 텐서플로우 알고리즘 종류 머신러닝 시스템의 종류는 굉장히 많으므로 다음 기준으로 넓은 범주에서 분류하면 이해해 도움이 된다.
- 사람의 감독하에 훈련하는 것인지 그렇지 않은 것인지(지도,비지도,준지도,강화 학습)
- 실시간으로 점진적인 학습을 하는지(안라인 학습과 배치 학습)
- 단순하게 알고 있는 데이터 포인트와 새 데이터 포인트를 비교하는 것인지 아니면 훈련 데이터셋에서 데이터 사이언티스트들 처럼 패턴을 발견하여 예측 모델을 만드는지(사례 기반 학습과 모델 기반 학습)
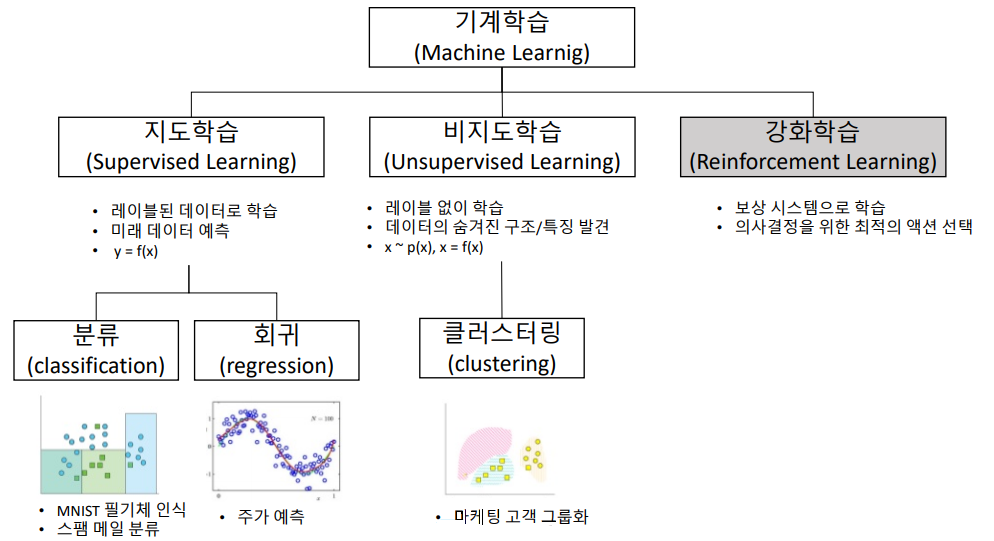
일단 아래에서는 지도 학습과 비지도 학습에 대해서 먼저 알아보고 넘어가겠다.
지도학습(Supervised learning)
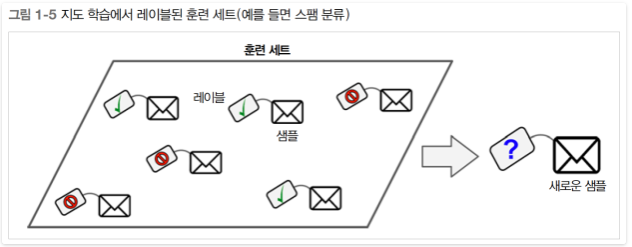
지도학습에는 알고리즘에 주입하는 훈련 데이터에 레이블(Label)이라는 원하는 답이 포함된다. (그림 1-5)
 분류(classification)가 전형적인 지도 학습 작업이며, 스팸 필터가 좋은 예이다. 스팸필터는 많은 메일 샘플과 소속 정보(스팸인지 아닌지)로 훈련되어야 하며, 어떻게 새 메일을 분류할지 학습해야 한다.
분류(classification)가 전형적인 지도 학습 작업이며, 스팸 필터가 좋은 예이다. 스팸필터는 많은 메일 샘플과 소속 정보(스팸인지 아닌지)로 훈련되어야 하며, 어떻게 새 메일을 분류할지 학습해야 한다.
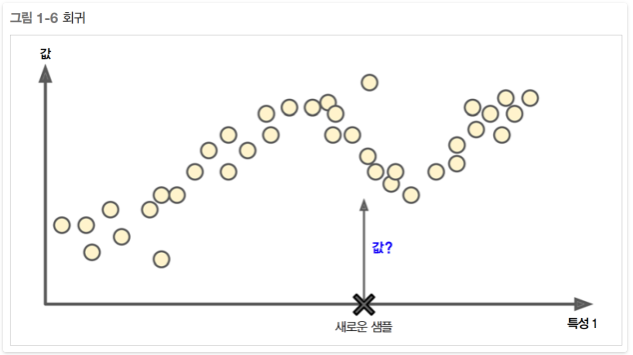
또 다른 전형적인 작업은 예측 변수(predictor variable)라 부르는 특성(feature)(주행거리, 연식, 브랜드 등)을 사용해 중고차 가격 같은 타깃수치를 예측하는 것이다. 이런 종류의 작업을 회귀(regression)라고 부른다.(그림 1-6) 시스템을 훈련시키려면 예측 변수와 레이블(중고차 가격)이 포함된 중고차 데이터가 많이 필요한다.
노트) 머신러닝에서 속성(attribute)은 데이터 타입(예를들면 주행거리, 연식 등)을 말한다. 특성(feature)는 문맥에 따라여러 의미를 갖지만 일반적으로 속성과 값이 합쳐진 것을 의미한다.(예를 들면 주행거리=15,000). 하지만 많은 사람들이 속성과 특성을 구분하지 않고 사용한다.
중요 지도학습(Supervised learning) 알고리즘
1. k-최근접 이웃(k-Nearest Neighbors. k-NN) : 가장 간단한 머신러닝 알고리즘. 훈련 데이터를 저장하는것이 모델을 만드는 과정의 전부이다. 새로운 데이터 포인트에 대해 예측 할 땐 알고리즘이 훈련 데이터셋에서 가장 가까운 데이터 포인트, 즉 최근접 이웃을 찾는다. 작은 데이터셋일 경우, 기본 모델로서 좋고 설명하기 쉬움
2. 선형회귀(Linear Regression) : 선형회귀 분석은 변수들 사이의 관계를 분석하는데 사용하는 통계학적 방법이다. 이 방법의 장점은 알고리즘의 개념이 복잡하지 않고 다양한 문제에 폭 넓게 적용할 수 있다는 것이다. 지도학습 중 가장 기본이 되는 알고리즘 중 하나이이며, 대용량 데이터셋 가능. 고차원 데이터에 적용 가능.
3. 로지스틱 회귀(Logistic Regression) - 분류에 사용하는 모델이다. - 선형 함수 결과를 시그모이드 함수를 이용하여 0 ~ 1 사이로 압축한다. - 이진 분류는 0.5보다 높을 때는 True, 그이하는 Flase로 하여 모델을 학습시킨다. - 시그모이드 함수를 사용한 크로스 엔트로피 비용함수의 미분 결과는 선형 함수를 사용한 MSE 비용함수의 미분과 동일하다. - 로지스틱 회귀는 다중 분류도 지원. - 분류(Classification) - 클래스 레이블을 예측한다. - 출력 결과는 이산적이다. - Binary Classification(이진 분류), Multiclass Classification(다중 분류) - ex) 스팸분류 , 암 진단, 꽃의 품종 판별, 손글씨 숫자 분류
일반적으로 회귀분석은 다음과 같은 실제 응용 프로그램에서 사용할 수 있다.
- 신용 점수
- 마케팅 캠페인의 성공률 측정
- 특정 제품의 매출 예측율
- 특정 날에 지진이 발생할 확율
4. 서포트 백터 머신(Support Vector Machines, SVM) : SVM은 바이너리 분류 알고리즘(binary classification algorithm)입니다. N차원 장소에서 2가지 유형의 점 집합이 주어지면 SVM은 (N-1) 차원의 초평면(hyperplane)을 생성하여, 이 점들을 두 그룹으로 분리한다. 종이에 선형적으로 분리 가능한 2가지 유형의 포인트가 있다고 가정하면 SVM은 이 점들을 2가지 유형으로 분리하고 모든 점들로부터 가능한 멀리 위치하는 직선을 발견 할 것 이다. 규모면에서 SVM을 사용하여 해결된 가장 큰 문제는 디스플레이 광고, 사람의 이미지 분해 인식, 이미지 기반 성별 탐지, 대규모 이미지 분류 등이다. 비슷한 의미의 특성으로 이뤄진 중간 규모 데이터셋에 잘맞음. 데이터 스케일 조정 필요. 매개변수에 민감.
5. 의사결정 트리(Decision Trees) : 의사 결정 트리는 의사 결정 지원 도구로, 우연한 이벤트 결과, 리소스 비용 및 유틸리티를 포함하여 트리와 같은 그래프 또는 의사 결정 모델 및 가능한 결과를 사용한다. 비즈니스 의사 결정의 관점에서, 의사 결정 트리는 대부분의 시간에 올바른 결정을 내릴 확률을 평가하기 위해 질문해야 하는 예/아니오 질문의 최소 수이다. 방법으로 논리적인 결론에 도달하기 위해 구조화되고 체계적인 방식으로 문제에 접근 할 수 있다.
6. 랜덤 포레스트(random forest) : 랜덤 포레스트는 분류, 회귀분석 등에 사용되는 앙상블 학습 방법의 일종으로, 훈련 과정에서 구성한 다수의 결정 트리로 부터 분류 또는 평균 예측치(회귀분석)를 출력함으로써 동작한다. 랜덤 포레스트 방법은 크게 다수의 결정 트리를 구성하는 학습 단계와 입력 벡터가 들어왔을 때, 분류하거나 예측하는 테스트 단계로 구성되어 있다. 랜덤 포레스트는 검출, 분류, 그리고 회귀 등 다양한 애플리케이션으로 활용되고 있다. 결정 트리 하나보다 거의 항상 좋은 성능을 냄. 안정적이고 강력함. 데이터스케일 조정 필요 없음. 고차원 희소 데이터에는 잘 안맞음.
7. 신경망/딥러닝(Neural networks/deep learning) : 신경망이라 알려진 알고리즘들은 최근 딥러닝이란 이름으로 다시 주목받고 있다. 딥러닝이 많은 머신러닝 애플리케이션에서 매우 희망적인 성과를 보여주고 있지만, 특정 분야에 정교하게 적용되어 있을때가 많다. 특별히 대용량 데이터셋에서 매우 복잡한 모델을 들 수 있음. 매개 변수 선택과 데이터 스케일에 민감. 큰 모델은 학습이 오래 걸림.
비지도 학습(Unsupervised learning)
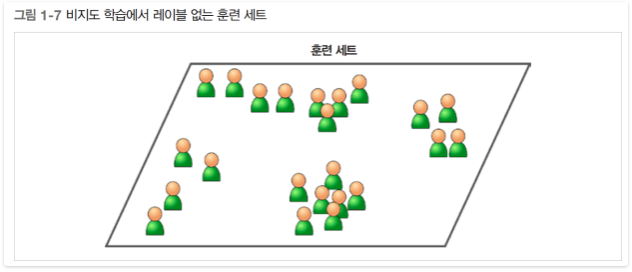
비지도 학습에는 말 그대로 훈련 데이터에 레이블(label)이 없다.(그림 1-7) 시스템이 아무런 도움 없이 학습한다.
중요 비지도 학습(Unsupervised learning) 알고리즘
- 군집
- k-평균(k-Means) k-means는 클러스터링 문제를 풀기 위한 비감독 학습 알고리즘이다. 이 알고리즘은 간단한 방법으로 주어진 데이터를 지정된 클러스터 갯수(k)로 그룹핑한다. 한 클러스터 내의 데이터들은 동일한 성질을 가지며 다른 그룹에 대하여 구별된다. 즉 한 클러스터 내의 모든 엘리먼트들은 클러스터 밖의 데이터보다 더 닮아 있다.
알고리즘의 결과는 센트로이드(centroid)라 불리는 K개의 포인트로서 서로 다른 그룹의 중심을 나타내며 데이터들은 K 클러스터 중 하나에만 속할 수 있다.한 클러스터 내의 모든 데이터들은 다른 센트로이드보다 자신의 센트로이드와의 거리가 더 가깝다.
클러스터를 구성하는데 직접 에러 함수를 최소화하려면 계산 비용이 매우 많이든다. (NP-hard 문제로 알려져 있음) 그래서 스스로 로컬 최소값에 빠르게 수렴할 수 있는 방법들이 개발되어 왔다. 가장 널리 사용되는 방법은 몇번의 반복으로 수렴되는 반복 개선(iterative refinement) 테크닉이다.
- 계층 군집 분석(Hierarchical Cluster Analysis, HCA) 계층 군집은 비슷한 군집끼지 묶어가면서 최종적으로는 하나의 케이스가 될때까지 군집을 묶는 클러스터링 이다. 군집간의 거리를 기반으로 클러스터링을 하는 알고리즘이며, K Means와는 다르게 군집의 수를 미리 정해주지 않아도 된다.
- 기댓값 최대화(Expectation Maximization, EM) 텐서플로우에서 제공하는지 확인 안됨.
- 시각화(Visualization)와 차원 축소(Dimensionality reduction)
- 주성분 분석(Principal Component Analysis. PCA)
- 커널(kernel)
- 지역적 선형 임베딩(Locally-Linear Embedding. LLE)
- t-SNE(t-distributed Stochastic Neigbor Embedding)
- 연관 규칙 학습(Association rule learning)
- 어프라이어리(Apriori)
- 이클렛(Eclat)
군집(Clustering)
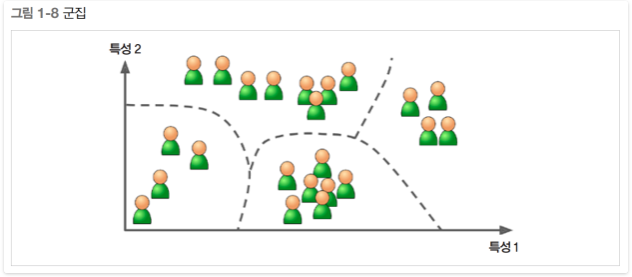
블로그 방문자에 대한 데이터가 많이 있다고 하자. 비슷한 방문자들을 그룹으로 묶기 위해 군집 알고리즘을 적용하려 한다.(그림 1-8). 하지만 방문자가 어떤 그룹에 속하는지 알고리즘에 알려줄 수 있는 데이터 포인트가 없다. 그래서 알고리즘이 스스로 방문자 사이의 연결고리를 찾는다. 예를들어 40%의 방문자가 만화책을 좋아하며 저녁때 블로그 글을 읽는 남성이고, 20%는 주말에 방문하는 공상과학을 좋아하는 젊은 사람임을 알게 될지도 모른다. 계층 군집(hierarchical clustering) 알고리즘을 사용하면 각 그룹을 더 작은 그룹으로 세분화 할 수 있다. 그러면 각 그룹에 맞춰 블로그에 글을 쓰는데 도움이 될 것이다.
시각화(Visualization)
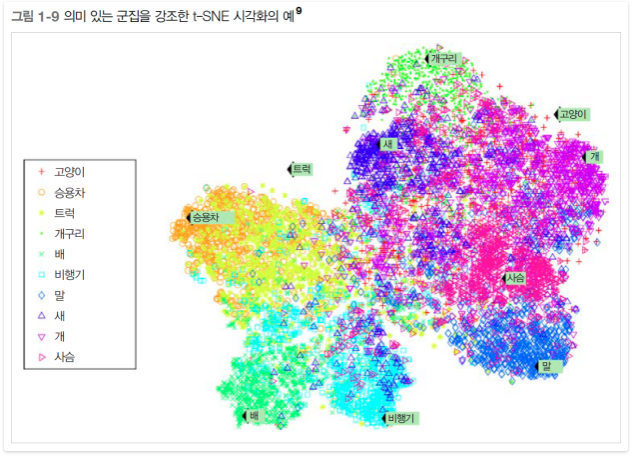
시각화 알고리즘도 비지도 학습 알고리즘의 좋은 예이다. 레이블이 없는 대규모의 고차원 데이터를 넣으면 도식화가 가능한 2D나 3D 표현을 만들어 준다.(그림 1-9). 이런 알고리즘은 가능한 한 구조를 그대로 유지하려 하므로(예를 들어 입력 공간에서 떨어져 있던 클러스터는 시각화된 그래프에서 겹쳐지지 않게 유지된다) 데이터가 어떻게 조직되어 있는지 이해할 수 있고 예상하지 못한 패턴을 발견할 수도 있다.
비슷한 작업으로는 너무 많은 정보를 잃지 않으면서 데이터를 간소화하려는 차원 축소(dimensioonality reduction)가 있다. 이렇게하는 한가지 방법은 상관관계가 있는 여러 특성을 하나로 합치는 것이다. 예를 들어 차의 주행거리는 연식과 매우 연관되어 있으므로 차원 축소 알고리즘으로 두 특성을 차의 마모 정도를 나타내는 하나의 특성으로 합칠 수 있다. 이를 특성 추출(Geature Extraction)이라고 한다.
참고) 머신러닝 알고리즘(지도학습 알고리즘)에 데이터를 주입하기 전에 차원축소 알고리즘을 사용하여 훈련 데이터의 차원을 줄이는 것이 유용할 때가 많다. 실행 속도가 훨씬 빨라지고 디스크와 메모리를 차지하는 공간도 줄고 경우에 따라 성능이 좋아지기도 한다.
연관규칙 학습(Association rule learning)
널리 사용되는 또다른 비지도 학습은 대량의 데이터에서 특성 간의 흥미로운 관계를 찾는 연관규칙 학습이다. 예를들어 내가 슈퍼마켓을 운영한다고 가정하자. 판매 기록에 연관 규칙을 적용하면 바비큐 소스와 감자를 구매한 사람이 스테이크도 구매하는 경향이 있다는 것을 찾을 지도 모른다.
또 하나의 중요한 비지도 학습은 이상치 탐지(anomaly detection)이다. 예를 득ㄹ어 부정 거래를 막기 위해 이상한 신용카드 거래를 감지하고, 제조 결함을 잡아내고, 학습 알고리즘에 주입하기 전에 데이터셋에서 이상한 값을 자동으로 제거하는 것 등이다. 머신러닝 모델은 정상 샘플로 훈련되고, 새로운 샘플이 정상 데이터인지 혹은 이상치인지 판단한다.

준지도 학습(semisupervised learning)
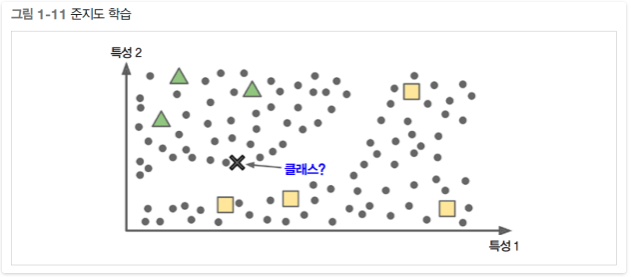
어떤 알고리즘은 레이블이 일부만 있는 데이터도 달룰 수 있다. 보통은 레이블이 없는 데이터가 많고, 레이블이 있는 데이터는 아주 조금이다. 이를 준지도 학습이라고 한다.(그림 1-11)
구글 포토 호스팅 서비스가 좋은 예이다. 이서비스에 가족사진을 모두 올리면 사람 A는 사진 1, 5, 11에 있고, 사람 B는 사진 2, 5, 7에 있다고 자동으로 인식한다. 이는 비지도 학습(군집)이다. 이제 필요한 것은 이 사람들이 누구인가 하는 정보이다. 사람마다 레이블이 하나씩만 주어지면 사진에 있는 모든 사람의 이름을 알 수 있고, 편리하게 사진을 찾을 수 있다.
대부분의 준지도 학습 알고리즘은 지도 학습과 비지도 학습의 조합으로 이루어져 있다. 예를들어 심층 신뢰 신경망(deep belief network. DBN)은 여러 겹으로 쌓은 제한된 볼츠만 머신(restricted Boltzmann machine. RBM)이라 불리는 비지도 학습에 기초한다. RBM이 비지도 학습 방식으로 순차적으로 훈련된 다음 전체 시스템이 지도 학습 방식으로 세밀하게 조정된다.
출처
머신러닝 엔지니어가 알아야 할 10가지 알고리즘
#머신러닝 엔지니어가 알아야 할 10가지 알고리즘
지도학습(Supervised Learning)
1. 의사 결정 트리(Decision Trees) : 의사 결정 트리는 의사 결정 지원 도구로, 우연한 이벤트 결과, 리소스 비용 및 유틸리티를 포함하여 트리와 같은 그래프 또는 의사 결정 모델 및 가능한 결과를 사용합니다. 비즈니스 의사 결정의 관점에서, 의사 결정 트리는 대부분의 시간에 올바른 결정을 내릴 확률을 평가하기 위해 질문해야 하는 예/아니오 질문의 최소 수입니다. 방법으로 논리적인 결론에 도달하기 위해 구조화되고 체계적인 방식으로 문제에 접근 할 수 있습니다.
2. 나이브베이즈 분류(Naive Bayes Classification) : 나이브베이즈 분류자(Naive Bayes classifier)는 특징들 사이에 강력한(순진한) 독립 가정을 가진 Bayes의 정리를 적용한 간단한 확률 분류자의 패밀리입니다. P(A|B)는 사후확률(posterior probability ), P(B|A)는 우도(likelihood), P(B)는 사전예측확률입니다. 실제 사례의 일부는 다음과 같습니다.
- 전자 메일을 스팸 또는 스팸이 아닌 것으로 표시
- 기술, 정치 또는 스포츠에 관한 뉴스 기사 분류
- 긍정적인 감정을 나타내는 텍스트나 부정적인 감정을 확인
- 얼굴 인식 소프트웨어
3. 보통 최소 자승 회귀(Ordinary Least Squares Regression, OLS회귀) : 통계를 알고 있다면 아마도 이전에 선형회귀(linear regression)를 들어 본 적이 있을 것입니다. 최소 자승(Least squares)은 선형회귀를 수행하는 방법입니다. 선형회귀는 점 집합을 통해 직선을 피팅하는 작업으로 생각할 수 있습니다. 이 작업을 수행 할 수 있는 여러 가지 전략이 있습니다. “보통 최소 자승” 전략은 다음과 같이 진행됩니다. - 선을 그릴 수 있고 각 데이터 점에 대해 점과 선 사이의 수직 거리를 측정 한 다음 이를 더할 수 있습니다; 딱 맞는 선은 이 거리의 합이 가능한 만큼 작을 것입니다. 선은 데이터를 맞추는데 사용하는 모델의 종류를 나타내며, 최소 자승은 최소화하는 오류 메트릭의 종류를 나타냅니다.
4. 로지스틱 회귀(Logistic Regression) : 로지스틱 회귀는 많은 설명변수(explanatory variable, 회귀분석에서는 독립변수)가 있거나 이항결과(binomial outcome)를 모델링하는 강력한 통계 방법입니다. 누적 로지스틱 분포(cumulative logistic distribution)라는 로지스틱 함수를 사용하여 확률을 추정하여 범주형 종속 변수(dependent variable)와 하나 이상의 독립 변수(independent variable) 간의 관계를 측정합니다.일반적으로 회귀분석은 다음과 같은 실제 응용 프로그램에서 사용할 수 있습니다.
- 신용 점수
- 마케팅 캠페인의 성공률 측정
- 특정 제품의 매출 예측율
- 특정 날에 지진이 발생할 확율
5. 서포트 벡터 머신(Support Vector Machines, SVM) : SVM은 바이너리 분류 알고리즘(binary classification algorithm)입니다. N차원 장소에서 2가지 유형의 점 집합이 주어지면 SVM은 (N-1) 차원의 초평면(hyperplane)을 생성하여, 이 점들을 두 그룹으로 분리합니다. 종이에 선형적으로 분리 가능한 2가지 유형의 포인트가 있다고 가정하면 SVM은 이 점들을 2가지 유형으로 분리하고 모든 점들로부터 가능한 멀리 위치하는 직선을 발견 할 것 입니다. 규모면에서 SVM을 사용하여 해결된 가장 큰 문제는 디스플레이 광고, 사람의 이미지 분해 인식, 이미지 기반 성별 탐지, 대규모 이미지 분류 등입니다.
6. 앙상블 방법(Ensemble Methods) : 앙상블 방법은 일련의 분류 기준을 구성한 알고리즘을 학습 한 후 예측에 대한 가중 투표(weighted vote)를 통해 새로운 데이터 포인트를 분류합니다. 원래의 앙상블 방법은 베이지안 평균 (Bayesian averaging)이지만 최근의 알고리즘에는 오류 수정 출력 코딩(error-correcting output coding), 배깅(bagging) 및 부스팅(boosting)이 포함됩니다. 그렇다면 앙상블 방법은 어떻게 작동하며 왜 개별 모델보다 우수할까요?
- 편의(bias, 실제값에 대한 추정값의 오차)를 평균화 : 당신이 민주주의를 중요시하는 투표와 공화당이 기울인 투표를 함께 평균한다면 어느 쪽이든 기대지 않는 평균의 것을 얻을 것입니다.
- 분산(variance)을 감소 : 일련의 모델에 대한 총체적 의견은 모델 중 하나의 단일 의견보다 덜 시끄럽습니다. 금융 분야에서이를 다양 화 (diversification)라고합니다. 많은 주식을 혼합 한 포트폴리오는 주식 중 하나만을 사용하는 것보다 훨씬 가변적입니다. 이것이 모델이 더 적은 데이터 포인트가 아닌 더 많은 데이터 포인트로 개선되는 이유입니다.
- 오버피팅(Overfit) 감소 : 오버핏이 없는 개별 모델이 있고 각 모델의 예측을 간단한 방법 (평균, 가중 평균, 로지스틱 회귀)으로 결합하는 경우에는 오버피팅이 발생할 여지가 없습니다.
비지도 학습(Unsupervised Learning)
1. 클러스터링 알고리즘(Clustering Algorithms) : 비지도 학습 알고리즘 중 가장 많이 사용하는 알고리즘이라고 한다. 클러스터링은 동일한 그룹(클러스터)의 개체가 다른 그룹의 개체보다 서로 비슷하도록 개체 집합을 그룹화하는 작업입니다 . 모든 클러스터링 알고리즘은 여러 가지가 있으며 이중 몇 개를 소개합니다.
- 중심 기반 알고리즘 (Centroid-based algorithms)
- 연결 기반 알고리즘 Connectivity-based algorithms)
- 밀도 기반 알고리즘 (Density-based algorithms)
- 확률적 (Probabilistic)
- 차원축소 (Dimensionality Reduction)
- 신경망 / 딥러닝 (Neural networks / Deep Learning)
2. 주성분 분석(Principal Component Analysis, PCA) : PCA는 직교 변환(orthogonal transformation)을 사용하여 상관 관계가 있는 변수의 관측치 집합을 주성분(principal components) 이라는 선형적으로 상관없는 변수 집합으로 변환하는 통계적 절차입니다. PCA는압축, 쉬운 학습, 시각화를 위한 데이터 단순화에 일부 응용됩니다. PCA로 진행할지 여부를 선택하기 위해서 도메인 지식이 매우 중요합니다. 데이터에 오류가 많은 경우 (PCA의 모든 구성 요소에는 상당한 편차가 있음)에는 적합하지 않습니다.
3. 특이값 분해 (Singular Value Decomposition, SVD) : 선형 대수학(linear algebra)에서 SVD는 실제 복잡한 행렬의 인수분해(factorization)입니다. 주어진 m * n 행렬 M에 대해 M = UΣV와 같은 분해(decomposition)가 존재합니다. 여기서 U와 V는 단위행렬(unitary matrices)이고 Σ는 대각행렬(diagonal matrix) 입니다. PCA는 실제로 SVD의 간단한 응용입니다. 컴퓨터 비전에서 최초의 얼굴 인식 알고리즘은 얼굴을 “고유체(Eigenface)”의 선형 조합(linear combination)으로 표현하고, 차원축소(dimensionality reduction)를 수행 한 다음 간단한 방법으로 얼굴을 신원과 일치시키기 위해 PCA 및 SVD를 사용했었습니다. 현대적인 방법은 훨씬 정교하지만 많은 사람들이 여전히 유사한 기술에 의존합니다.
4. 독립 성분 분석 (Independent Component Analysis, ICA) : ICA는 무작위 변수(random variables), 측정값(measurements) 또는 신호(signals) 세트의 기초가 되는 숨겨진 요인을 밝혀 내기 위한 통계 기법입니다. ICA는 일반적으로 샘플의 대규모 데이터베이스로 제공되는 관측된 다변량 데이터(observed multivariate data)에 대한 생성 모델을 정의합니다. 모델에서 데이터 변수는 미지의 잠재 변수의 선형 혼합으로 가정되며 혼합 시스템도 알 수 없습니다. 잠재 변수는 가우스(Gaussian)가 아니며 상호 독립적인 것으로 가정되며 관측된 데이터의 독립적인 구성 요소라고 합니다. ICA는 PCA와 관련이 있지만, 이 고전적인 방법이 완전히 실패할 때 소스의 기본 요소를 찾을 수있는 훨씬 더 강력한 기술입니다. ICA는 디지털 이미지, 문서 데이터베이스, 경제 지표 및 심리 측정에 응용됩니다.
출처
머신러닝 삽질기 시작
#개발 삽질기 블로그 오픈 앞으로 빅데이터, 머신러닝 연구 및 개발 가이드를 작성하기 위해 블로그를 만들었다.
현재 회사에서 텐서플로우 및 구글 Cloud ML Engine 연구 과제를 진행 중이다. 관련 자료들을 포스팅 해보겠다.
The Theme features:
- Gulp
- SASS
- Sweet Scroll
- Particle.js
- BrowserSync
- Font Awesome and Devicon icons
- Google Analytics
- Info Customization
Basic Setup
- Install Jekyll
- Fork the Particle Theme
- Clone the repo you just forked.
- Edit
_config.ymlto personalize your site.
Site and User Settings
You have to fill some informations on _config.yml to customize your site.
# Site settings
description: A blog about lorem ipsum dolor sit amet
baseurl: "" # the subpath of your site, e.g. /blog/
url: "http://localhost:3000" # the base hostname & protocol for your site
# User settings
username: Lorem Ipsum
user_description: Anon Developer at Lorem Ipsum Dolor
user_title: Anon Developer
email: anon@anon.com
twitter_username: lorem_ipsum
github_username: lorem_ipsum
gplus_username: lorem_ipsum
Don’t forget to change your url before you deploy your site!
Color and Particle Customization
- Color Customization
- Edit the sass variables
- Particle Customization
- Edit the json data in particle function in app.js
- Refer to Particle.js for help
Running the blog in local
In order to compile the assets and run Jekyll on local you need to follow those steps:
- Install NodeJS
- Run
npm install - Run
gulp
Questions
Having any issues file a GitHub Issue.
License
This theme is free and open source software, distributed under the The MIT License. So feel free to use this Jekyll theme anyway you want.
Credits
This theme was partially designed with the inspiration from these fine folks
텐서플로우란?
인공지능(AI),머신러닝,딥러닝 등 머신러닝 관련 용어들은 누구나 다 많이 들어보았을 것이다. 텐서플로우는 머신러닝을 쉽게 다루기 위한 도구라고 이해해볼수 있다.
텐서플로우 용어사전
#텐서플로우 용어사전
Google BigQuery 콘솔(WEB UI) 가이드
#Google BigQuery 콘솔(WEB UI) 가이드
머신러닝 삽질기!
Next you can update your site name, avatar and other options using the _config.yml file in the root of your repository (shown below).